 UGISS User Group Italiano SQL Server
UGISS User Group Italiano SQL Server
Vedere il supporto nativo di JSON su SQLServer 2016 (e anche su Azure SQLDatabase) mi ha fatto pensare che magari era possibile averlo in forma semplificata anche su versioni precedenti.
Tutto è nato dalla necessità di gestire un flusso di dati con una Stored Procedure in arrivo da una WebAPI. Inizialmente la WebAPI, dopo aver fatto gli opportuni controlli logici di validità, deserializzava il flusso per poi formattare una stringa da passare alla Stored Procedure.
La gestione del parametro in ingresso alla SP come TABLE non sembrava possibile utilizzando EF6, quindi si è optato di mantenere la SP nello stato originale, ovvero con la stringa e altri parametri per i caratteri separatori.
la struttura della stringa json era:
[{memberId: id1, percentage: val1}, {memberId: id2, percentage: val2}, {memberId: id3, percentage: val3} … {memberId: idn, percentage: valn}]
la stringa formattata diventava:
id1|val1;id2|val2;id3|val3; …. idn|valn
la stored procedure era la seguente:
ALTER PROCEDURE [dbo].[uspPippo]
@Player varchar(5000)
, @DelimiterPlayer char(1)
, @DelimiterPercentage char(1)
WITH EXECUTE AS CALLER
--, ENCRYPTION
AS
BEGIN TRY
END TRY
BEGIN CATCH
-- Rollback della transazione
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END
EXECUTE [Job].[Log_uspLogError];
THROW;
END CATCH
a questo punto la stringa veniva parsata e splittata a dovere usando i caratteri separatori passati. Gestione alquanto macchinosa che necessitava anche di una @TABLE temporanea.
-- Extracting Players ids
DECLARE @PlayerTable TABLE (MemberID INT NULL, MemberIDChar varchar(10), Percentage Decimal(5,2) NULL, PercentageChar varchar(10), IsValid INT);
WITH Split(stpos,endpos,midpos)
AS(
SELECT 0 AS stpos, CHARINDEX(@DelimiterPlayer,@Player) AS endpos, CHARINDEX(@DelimiterPercentage,@Player) AS midpos
UNION ALL
SELECT endpos+1, CHARINDEX(@DelimiterPlayer,@Player,endpos+1), CHARINDEX(@DelimiterPercentage,@Player,midpos+1)
FROM Split
WHERE endpos > 0
)
INSERT INTO @PlayerTable (MemberID, MemberIDChar, Percentage, PercentageChar, IsValid)
SELECT NULL, SUBSTRING(@Player,stpos,COALESCE(NULLIF(midpos,0),LEN(@Player)+1)-stpos)
, NULL, SUBSTRING(@Player,midpos+1,COALESCE(NULLIF(endpos,0),LEN(@Player)+1)-midpos-1)
, ISNUMERIC(SUBSTRING(@Player,stpos,COALESCE(NULLIF(midpos,0),LEN(@Player)+1)-stpos)) + ISNUMERIC(SUBSTRING(@Player,midpos+1,COALESCE(NULLIF(endpos,0),LEN(@Player)+1)-midpos-1))
FROM Split;
UPDATE @PlayerTable SET MemberID = CONVERT(INT, MemberIDChar), Percentage = CONVERT(DECIMAL(5,2), PercentageChar)
WHERE IsValid = 2;
ed ecco il colpo di matto, perchè non tenere il formato JSON che già arriva alla WebAPI e gestirlo direttamente nella SP, così al momento in cui si passerà a Azure SQL Database (o a SQLServer 2016) questo punto sarà facilmente modificabile e trasparente all’applicazione chiamante. Detto fatto, rimossa tutta la parte di serializzazione JSON lato WebAPI per la sola scrittura della stringa formattata, rimozione della cozzaglia di codice lato SP e rimozione dei due parametri usati per i caratteri separatore.
Oh che bel codice pulito, ma mancava una cosa: il parser JSON che ricordiamo essere presente solo dalla versione SQLServer2016.
Ok, scovato un parser che fa al caso nostro (https://www.simple-talk.com/sql/t-sql-programming/consuming-json-strings-in-sql-server/):
CREATE FUNCTION [dbo].[ufParseJSON](@JSON NVARCHAR(MAX))
RETURNS @hierarchy TABLE
(
element_id INT IDENTITY(1, 1) NOT NULL, /* internal surrogate primary key gives the order of parsing and the list order */
sequenceNo [int] NULL, /* the place in the sequence for the element */
parent_ID INT,/* if the element has a parent then it is in this column. The document is the ultimate parent, so you can get the structure from recursing from the document */
Object_ID INT,/* each list or object has an object id. This ties all elements to a parent. Lists are treated as objects here */
NAME NVARCHAR(2000),/* the name of the object */
StringValue NVARCHAR(MAX) NOT NULL,/*the string representation of the value of the element. */
ValueType VARCHAR(10) NOT null /* the declared type of the value represented as a string in StringValue*/
)
AS
BEGIN
DECLARE
@FirstObject INT, --the index of the first open bracket found in the JSON string
@OpenDelimiter INT,--the index of the next open bracket found in the JSON string
@NextOpenDelimiter INT,--the index of subsequent open bracket found in the JSON string
@NextCloseDelimiter INT,--the index of subsequent close bracket found in the JSON string
@Type NVARCHAR(10),--whether it denotes an object or an array
@NextCloseDelimiterChar CHAR(1),--either a '}' or a ']'
@Contents NVARCHAR(MAX), --the unparsed contents of the bracketed expression
@Start INT, --index of the start of the token that you are parsing
@end INT,--index of the end of the token that you are parsing
@param INT,--the parameter at the end of the next Object/Array token
@EndOfName INT,--the index of the start of the parameter at end of Object/Array token
@token NVARCHAR(200),--either a string or object
@value NVARCHAR(MAX), -- the value as a string
@SequenceNo int, -- the sequence number within a list
@name NVARCHAR(200), --the name as a string
@parent_ID INT,--the next parent ID to allocate
@lenJSON INT,--the current length of the JSON String
@characters NCHAR(36),--used to convert hex to decimal
@result BIGINT,--the value of the hex symbol being parsed
@index SMALLINT,--used for parsing the hex value
@Escape INT --the index of the next escape character
DECLARE @Strings TABLE /* in this temporary table we keep all strings, even the names of the elements, since they are 'escaped' in a different way, and may contain, unescaped, brackets denoting objects or lists. These are replaced in the JSON string by tokens representing the string */
(
String_ID INT IDENTITY(1, 1),
StringValue NVARCHAR(MAX)
)
SELECT--initialise the characters to convert hex to ascii
@characters='0123456789abcdefghijklmnopqrstuvwxyz',
@SequenceNo=0, --set the sequence no. to something sensible.
/* firstly we process all strings. This is done because [{} and ] aren't escaped in strings, which complicates an iterative parse. */
@parent_ID=0;
WHILE 1=1 --forever until there is nothing more to do
BEGIN
SELECT
@start=PATINDEX('%[^a-zA-Z]["]%', @json collate SQL_Latin1_General_CP850_Bin);--next delimited string
IF @start=0 BREAK --no more so drop through the WHILE loop
IF SUBSTRING(@json, @start+1, 1)='"'
BEGIN --Delimited Name
SET @start=@Start+1;
SET @end=PATINDEX('%[^\]["]%', RIGHT(@json, LEN(@json+'|')-@start) collate SQL_Latin1_General_CP850_Bin);
END
IF @end=0 --no end delimiter to last string
BREAK --no more
SELECT @token=SUBSTRING(@json, @start+1, @end-1)
--now put in the escaped control characters
SELECT @token=REPLACE(@token, FROMString, TOString)
FROM
(SELECT
'\"' AS FromString, '"' AS ToString
UNION ALL SELECT '\\', '\'
UNION ALL SELECT '\/', '/'
UNION ALL SELECT '\b', CHAR(08)
UNION ALL SELECT '\f', CHAR(12)
UNION ALL SELECT '\n', CHAR(10)
UNION ALL SELECT '\r', CHAR(13)
UNION ALL SELECT '\t', CHAR(09)
) substitutions
SELECT @result=0, @escape=1
--Begin to take out any hex escape codes
WHILE @escape>0
BEGIN
SELECT @index=0,
--find the next hex escape sequence
@escape=PATINDEX('%\x[0-9a-f][0-9a-f][0-9a-f][0-9a-f]%', @token collate SQL_Latin1_General_CP850_Bin)
IF @escape>0 --if there is one
BEGIN
WHILE @index<4 --there are always four digits to a \x sequence
BEGIN
SELECT --determine its value
@result=@result+POWER(16, @index)
*(CHARINDEX(SUBSTRING(@token, @escape+2+3-@index, 1),
@characters)-1), @index=@index+1 ;
END
-- and replace the hex sequence by its unicode value
SELECT @token=STUFF(@token, @escape, 6, NCHAR(@result))
END
END
--now store the string away
INSERT INTO @Strings (StringValue) SELECT @token
-- and replace the string with a token
SELECT @JSON=STUFF(@json, @start, @end+1,
'@string'+CONVERT(NVARCHAR(5), @@identity))
END
-- all strings are now removed. Now we find the first leaf.
WHILE 1=1 --forever until there is nothing more to do
BEGIN
SELECT @parent_ID=@parent_ID+1
--find the first object or list by looking for the open bracket
SELECT @FirstObject=PATINDEX('%[{[[]%', @json collate SQL_Latin1_General_CP850_Bin)--object or array
IF @FirstObject = 0 BREAK
IF (SUBSTRING(@json, @FirstObject, 1)='{')
SELECT @NextCloseDelimiterChar='}', @type='object'
ELSE
SELECT @NextCloseDelimiterChar=']', @type='array'
SELECT @OpenDelimiter=@firstObject
WHILE 1=1 --find the innermost object or list...
BEGIN
SELECT
@lenJSON=LEN(@JSON+'|')-1
--find the matching close-delimiter proceeding after the open-delimiter
SELECT
@NextCloseDelimiter=CHARINDEX(@NextCloseDelimiterChar, @json,
@OpenDelimiter+1)
--is there an intervening open-delimiter of either type
SELECT @NextOpenDelimiter=PATINDEX('%[{[[]%',
RIGHT(@json, @lenJSON-@OpenDelimiter)collate SQL_Latin1_General_CP850_Bin)--object
IF @NextOpenDelimiter=0
BREAK
SELECT @NextOpenDelimiter=@NextOpenDelimiter+@OpenDelimiter
IF @NextCloseDelimiter<@NextOpenDelimiter
BREAK
IF SUBSTRING(@json, @NextOpenDelimiter, 1)='{'
SELECT @NextCloseDelimiterChar='}', @type='object'
ELSE
SELECT @NextCloseDelimiterChar=']', @type='array'
SELECT @OpenDelimiter=@NextOpenDelimiter
END
---and parse out the list or name/value pairs
SELECT
@contents=SUBSTRING(@json, @OpenDelimiter+1,
@NextCloseDelimiter-@OpenDelimiter-1)
SELECT
@JSON=STUFF(@json, @OpenDelimiter,
@NextCloseDelimiter-@OpenDelimiter+1,
'@'+@type+CONVERT(NVARCHAR(5), @parent_ID))
WHILE (PATINDEX('%[A-Za-z0-9@+.e]%', @contents collate SQL_Latin1_General_CP850_Bin))0
BEGIN
IF @Type='Object' --it will be a 0-n list containing a string followed by a string, number,boolean, or null
BEGIN
SELECT
@SequenceNo=0,@end=CHARINDEX(':', ' '+@contents)--if there is anything, it will be a string-based name.
SELECT @start=PATINDEX('%[^A-Za-z@][@]%', ' '+@contents collate SQL_Latin1_General_CP850_Bin)--AAAAAAAA
SELECT @token=SUBSTRING(' '+@contents, @start+1, @End-@Start-1),
@endofname=PATINDEX('%[0-9]%', @token collate SQL_Latin1_General_CP850_Bin),
@param=RIGHT(@token, LEN(@token)-@endofname+1)
SELECT
@token=LEFT(@token, @endofname-1),
@Contents=RIGHT(' '+@contents, LEN(' '+@contents+'|')-@end-1)
SELECT @name=stringvalue FROM @strings
WHERE string_id=@param --fetch the name
END
ELSE
SELECT @Name=null,@SequenceNo=@SequenceNo+1
SELECT
@end=CHARINDEX(',', @contents)-- a string-token, object-token, list-token, number,boolean, or null
IF @end=0
SELECT @end=PATINDEX('%[A-Za-z0-9@+.e][^A-Za-z0-9@+.e]%', @Contents+' ' collate SQL_Latin1_General_CP850_Bin)
+1
SELECT
@start=PATINDEX('%[^A-Za-z0-9@+.e][A-Za-z0-9@+.e]%', ' '+@contents collate SQL_Latin1_General_CP850_Bin)
--select @start,@end, LEN(@contents+'|'), @contents
SELECT
@Value=RTRIM(SUBSTRING(@contents, @start, @End-@Start)),
@Contents=RIGHT(@contents+' ', LEN(@contents+'|')-@end)
IF SUBSTRING(@value, 1, 7)='@object'
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT @name, @SequenceNo, @parent_ID, SUBSTRING(@value, 8, 5),
SUBSTRING(@value, 8, 5), 'object'
ELSE
IF SUBSTRING(@value, 1, 6)='@array'
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT @name, @SequenceNo, @parent_ID, SUBSTRING(@value, 7, 5),
SUBSTRING(@value, 7, 5), 'array'
ELSE
IF SUBSTRING(@value, 1, 7)='@string'
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, stringvalue, 'string'
FROM @strings
WHERE string_id=SUBSTRING(@value, 8, 5)
ELSE
IF @value IN ('true', 'false')
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, 'boolean'
ELSE
IF @value='null'
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, 'null'
ELSE
IF PATINDEX('%[^0-9]%', @value collate SQL_Latin1_General_CP850_Bin)>0
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, 'real'
ELSE
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, 'int'
if @Contents=' ' Select @SequenceNo=0
END
END
INSERT INTO @hierarchy (NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT '-',1, NULL, '', @parent_id-1, @type
--
RETURN
END
Benissimo! funziona egregiamente per una struttura semplice, ma … (c’è sempre un ma) … la tabella di ritorno è così strutturata e popolata:
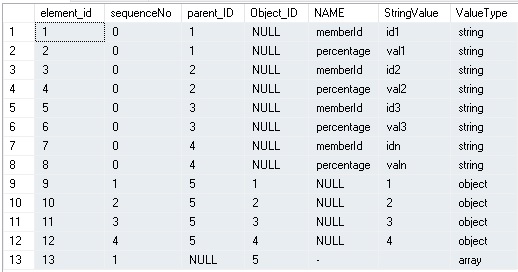
Di difficile gestione per metterla in join con altre tabelle del database per fare il MERGE e/o qualsiasi altra elaborazione orientata al SET (un cursore avrebbe fatto miracoli, ma non avremmo sfruttato a pieno le potenzialità dell’engine). La tabella risultante doveva essere strutturata e popolata come in precedenza, ovvero:
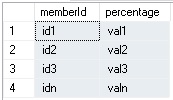
Cambiare il parser per calarlo nella specifica problematica non sarebbe stata una buona idea, ci saremo trovati ben presto con k parser specifici. dopo tutto il 2016 ha un solo parser .. quindi sfruttando le potenzialità del PIVOT ecco la soluzione:
WITH CTE (number, field, fieldValue) AS (
SELECT parent_ID AS number, NAME AS field, StringValue AS fieldValue
FROM dbo.ufParseJSON(@jsonValue)
WHERE [Object_ID] IS NULL
)
SELECT [memberId], [percentage]
FROM
(SELECT number, field, fieldValue
FROM CTE) AS SourceTable
PIVOT
(
MIN(fieldValue)
FOR field IN ([memberId], [percentage])
) AS PivotTable;
A questo punto la tabella risultante è tale e quale a quella in precedenza, senza però aver necessità di una TABLE temporanea. La scomodità è quella di ripetere i nomi dei campi due volte, ma la semplicità di cambiamento ne ripaga lo sforzo.
Al passaggio ad Azure SQL Database (o SQLServer 2016) il codice diventerà semplicemente questo:
SELECT [memberId], [percentage]
FROM OPENJSON(@jsonValue)
WITH (memberId int 'strict $.memberId',
percentage Decimal(5,2) '$.percentage')
Infine anche il formattare una stringa in formato JSON è gestibile e facilmente upgradabile:
SELECT '[' + STUFF ((SELECT ',{ "memberId": ' + cast(memberId as varchar(50)) + ', "percentage": "' + cast(percentage as varchar(50)) + ' }'
FROM MyTable
ORDER BY id FOR XML PATH('')), 1, 1, '') + ']';
Anche in questo caso, quando si passa a Azure SQL Database (o SQL Server 2016) il codice diventerà semplicemente questo:
SELECT [memberId], [percentage]
FROM MyTable
FOR JSON PATH;
In conclusione è possibile semplificare la gestione del passaggio di dati in formato JSON verso Stored Procedure e nel caso di upgrade di versione, il costo della modifica sarà contenuto, almeno in questo contesto.