 UGISS User Group Italiano SQL Server
UGISS User Group Italiano SQL Server
In questo articolo parleremo del concetto noto con il nome di SARGability arricchendolo di alcune considerazioni sulla trattazione dei valori NULL su cui ho avuto modo di ragionare dopo aver partecipato ad una sessione di Itzik Ben-Gan e dalla quale ho tratto ispirazione.
Wikipedia definisce Sargable una condizione (o predicato) di una query se l’engine del DBMS può sfruttare un indice per accelerare l’esecuzione della query. Il termine Sargable deriva dalla contrazione di Search ARGument ABLE.
Una query le cui condizioni (o predicati) non possano produrre ricerche indicizzate su un particolare range di righe (Index Seek) è nota come query non-sargable. In genere, le query non-sargable non sono ottimizzate, quindi uno dei passaggi nell’ottimizzazione delle query è convertirle in sargable. L’effetto della ricerca sull’indice è simile a quello che si ha cercando un termine specifico in un libro sprovvisto di indici, si è costretti ad iniziare ogni volta dalla prima pagina (Index Scan), invece di accedere ad un elenco di pagine specifiche identificate dall’indice.
Perché è importante scrivere query sargable? Il tempo di esecuzione di una query si può considerare (con un minimo di approssimazione) proporzionale al numero di pagine lette. Accessi a pagine specifiche dell’indice riducono la probabilità di leggere record interessati da una transazione attiva, sui quali esiste un lock. Una concorrenza maggiore permette di far lavorare insieme un numero maggiore di operatori.
Consideriamo la query seguente che estrae gli ordini fornitore dalla tabella Purchasing.PurchaseOrders del database WideWorldImporters e li restituisce in ordine crescente per la colonna ExpectedDeliveryDate.
SELECT
PurchaseOrderID, ExpectedDeliveryDate
FROM
Purchasing.PurchaseOrders
ORDER BY
ExpectedDeliveryDate;By default le righe con la colonna ExpectedDeliveryDate valorizzata a NULL verranno estratte per prime, si tratta di una scelta implementativa del linguaggio T-SQL che considera, in questo caso, il valore NULL minore di qualsiasi data.
Per questa query si desidera invertire l’ordine di presentazione dei dati, presentando per prime le righe aventi ExpectedDeliveryDate con valori diversi da NULL in ordine crescente e successivamente le righe con ExpectedDeliveryDate valorizzata con NULL. Come possiamo fare? Una possibile soluzione è quella di applicare l’espressione CASE all’interno della clausola ORDER BY.
SELECT
PurchaseOrderID, ExpectedDeliveryDate
FROM
Purchasing.PurchaseOrders
ORDER BY
CASE
WHEN (ExpectedDeliveryDate IS NOT NULL) THEN 0 ELSE 1
END;La query che otteniamo non è sargable, utilizza l’indice IX_Purchasing_PurchaseOrders_ExpectedDeliveryDate per la colonna ExpectedDeliveryDate su cui viene effettuata una scansione (Index Scan) al posto di un accesso puntale (Index Seek) ottimizzato.
La figura seguente illustra il piano di esecuzione della query (non-sargable).

Come possiamo rendere questa query sargable mantenendo il pre-requisito sull’ordinamento?
Si può dividere la query in due query, dalla prima verranno estratte le righe con valori di ExpectedDeliveryDate diversi da NULL, dalla seconda query verranno estratte le righe con valori NULL in ExpectedDeliveryDate. La clausola UNION ALL permetterà di unire i dataset e la successiva clausola ORDER BY applicherà l’ordinamento richiesto.
SELECT
PurchaseOrderID, ExpectedDeliveryDate, SortOrder = 0
FROM
Purchasing.PurchaseOrders
WHERE
ExpectedDeliveryDate IS NOT NULL
UNION ALL
SELECT
PurchaseOrderID, ExpectedDeliveryDate, SortOrder = 1
FROM
Purchasing.PurchaseOrders
WHERE
ExpectedDeliveryDate IS NULL
ORDER BY
SortOrder, ExpectedDeliveryDate;Eseguendo la query di osserva che l’indice IX_Purchasing_PurchaseOrders_ExpectedDeliveryDate viene acceduto due volte per leggere un particolare range di righe (Index Seek). Il primo accesso restituirà le righe con valori diversi da NULL in ExpectedDeliveryDate. Il secondo accesso restituirà le righe con il valore NULL nella colonna ExpectedDeliveryDate. I due dataset vengono uniti con l’operatore Merge Join come illustrato nella figura seguente. La query è sargable.
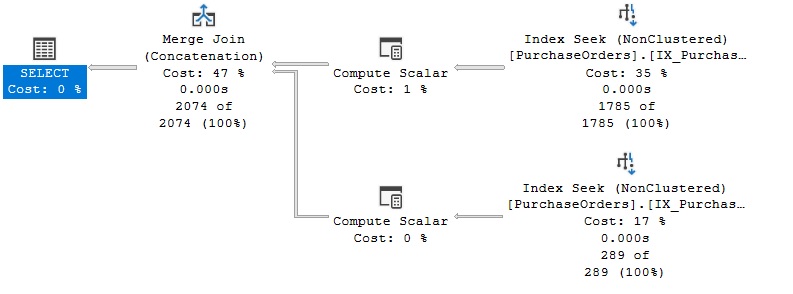
Ora si desidera implementare una stored procedure in grado di estrarre gli ordini fornitore in consegna ad una certa data e quelli la cui data di consegna è indefinita (NULL). Il seguente codice T-SQL implementa la stored procedure sp_undefined_deliverydate nello schema Purchasing.
CREATE PROCEDURE Purchasing.sp_undefined_deliverydate
(@DeliveryDate Date)
AS BEGIN
SELECT
PurchaseOrderID, ExpectedDeliveryDate
FROM
Purchasing.PurchaseOrders
WHERE
ExpectedDeliveryDate = @DeliveryDate;
END;Cosa accade se la stored procedure viene eseguita con il parametro @DeliveryDate valorizzato a NULL?
EXEC Purchasing.sp_undefined_deliverydate @DeliveryDate = NULL;L’operatore di confronto “=” che si troverà ad operare con l’opzione ANSI_NULLS impostata a ON (default per ogni connessione) valuterà ogni valore NULL diverso da ogni altro NULL. Quando si troverà a valutare l’espressione NULL = NULL (?) restituirà false.
Il dataset restituito sarà vuoto. Dal punto di vista delle performance, la query è sargable ma deve essere modificata per gestire correttamente i NULL. Qualcuno di voi avrà pensato di utilizzare la funzione T-SQL ISNULL che restituisce un valore specificato qualora si incontri un record con un valore NULL nella colonna passata come primo parametro di input. La stored procedure viene quindi modificata come riportato di seguito.
ALTER PROCEDURE Purchasing.sp_undefined_deliverydate
(@DeliveryDate Date)
AS BEGIN
SELECT
PurchaseOrderID, ExpectedDeliveryDate
FROM
Purchasing.PurchaseOrders
WHERE
ISNULL(ExpectedDeliveryDate, '99991231') = ISNULL(@DeliveryDate, '99991231');
END;Se la stored procedure viene ora eseguita con il parametro @DeliveryDate valorizzato a NULL il dataset restituito è corretto ma la query interna non è sargable come illustra il piano di esecuzione nella figura seguente.
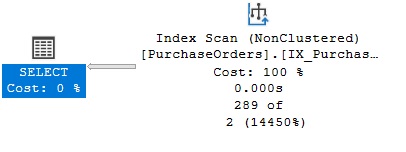
Sì può ottimizzare la query di estrazione dati rendendola sargable in modo elegante ed efficiente?
L’operatore T-SQL INTERSECT ci viene in aiuto in questi casi. INTERSECT restituisce le righe distinte che vengono rilevate nelle query di input a sinistra e a destra dell’operatore, come suggerisce il nome dell’operatore viene restituita l’intersezione dei dataset forniti in input.
La stored procedure viene quindi modificata come riportato di seguito.
ALTER PROCEDURE Purchasing.sp_undefined_deliverydate
(@DeliveryDate Date)
AS BEGIN
SELECT
PurchaseOrderID, ExpectedDeliveryDate
FROM
Purchasing.PurchaseOrders
WHERE
EXISTS(SELECT ExpectedDeliveryDate INTERSECT SELECT @DeliveryDate);
END;Ripetiamo l’esecuzione della stored procedure..
EXEC Purchasing.sp_undefined_deliverydate @DeliveryDate = NULL;Il predicato nella query di estrazione dati è sargable, il piano di esecuzione illustrato nella figura seguente mostra ora l’operatore Index Seek applicato all’indice IX_Purchasing_PurchaseOrders_ExpectedDeliveryDate, la query è sargable.
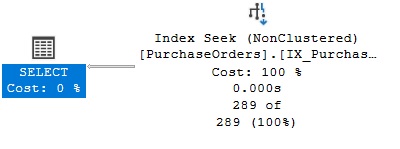
Anche le conversioni implicite tra tipi di dato possono rendere non sargable le condizioni di una query, per maggiori dettagli potete leggere questi articoli:
- Conversioni implicite: cosa sono e che impatto hanno sulle nostre query
- Conversioni implicite: La plan cache ci svela quante sono e dove avvengono
Conclusioni
Uno degli step del processo di ottimizzazione query è quello di convertire le condizioni (o predicati) delle query in condizioni sargale.
La trattazione dei valori NULL merita sempre di essere verificata specialmente quando si utilizzano parametri passati a funzioni o stored procedure.
L’operatore INTERSECT fornisce un pattern di applicazione quando è necessario eseguire l’intersezione di due insiemi, anche quando uno dei due insiemi è vuoto.