 UGISS User Group Italiano SQL Server
UGISS User Group Italiano SQL Server
Introduzione
Parameter Sensitive Plan (PSP) Optimization è una delle funzionalità introdotte da SQL Server 2022 e si colloca nella famiglia di funzionalità note con il nome di Intelligent Query Processing che migliorano le prestazioni dei carichi di lavoro esistenti senza modifiche al codice applicativo. Intelligent Query Processing (potenziato anche in SQL Server 2019) è l’erede della precedente tecnologia nota con il nome di Adaptive Query Processing di cui è disponibile il video Query Processing improvements in the latest versions of SQL Server sul canale UGISS di Vimeo.
Parameter Sensitive Plan (PSP) Optimization
Parameter Sensitive Plan (PSP) Optimization in SQL Server 2022 potenzia ulteriormente Intelligent Query Processing affrontando lo scenario in cui un singolo piano di esecuzione memorizzato nella cache per una query con parametri non è ottimale per tutti i possibili valori che tali parametri possono assumere.
Questa problematica è correlata al meccanismo di salvataggio e riutilizzo dei piani di esecuzione attuato da SQL Server. Il meccanismo di salvataggio e riutilizzo dei piani di esecuzione ha l’obiettivo di aumentare il tempo di risposta delle query; SQL Server non dovrà compilare un nuovo piano a ogni esecuzione della stessa query perché troverà in cache quello precedentemente salvato e parametrizzato. Questa tecnica ottimizza il tempo di compilazione di una query ma in presenza di distribuzioni di dati non uniformi può produrre un degrado delle performance, fenomeno noto con il nome di Parameter Sniffing (o Parameter Sensitivity). Maggiori informazioni sono disponibili nell’articolo Queries that have parameter sensitive plan (PSP) problems.
Parameter Sensitive Plan (PSP) Optimization permette di mantenere nella plan cache più piani di esecuzione attivi per una singola query parametrizzata, ogni piano di esecuzione sarà ottimizzato e ospiterà dimensioni di dati diverse in funzione dei valori assunti dai parametri. Ogni volta venga rilevata la necessità di utilizzare un piano di esecuzione diverso da quello presente in cache per una query parametrica, SQL Server calcolerà il piano di esecuzione ottimale per gli attuali valori assunti dai parametri.
Predisposizione dell’ambiente di test
Per dimostrare il funzionamento di Parameter Sensitive Plan (PSP) Optimization utilizzeremo il database PSP che può essere creato in una istanza SQL Server 2022 con lo script seguente.
USE [master];
GO
-- Drop database PSP if exists
IF (DB_ID('PSP') IS NOT NULL)
BEGIN
ALTER DATABASE [PSP]
SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [PSP];
END;
GO
CREATE DATABASE [PSP]
ON PRIMARY
(
NAME = N'PSPData'
,FILENAME = N'C:\SQL\DBs\PSPData.mdf'
)
LOG ON
(
NAME = N'PSPLog'
,FILENAME = N'C:\SQL\DBs\PSPLog.ldf'
);
GO
ALTER DATABASE [PSP] SET RECOVERY SIMPLE;
GOAggiungiamo la tabella dbo.Tab_A all’interno del database PSP appena creato. Il seguente script effettua la creazione della tabella e l’inserimento di alcuni dati di esempio.
USE [PSP];
GO
DROP TABLE IF EXISTS dbo.Tab_A;
GO
CREATE TABLE dbo.Tab_A
(
Col1 INTEGER
,Col2 INTEGER
,Col3 BINARY(2000)
);
GO
-- Insert some data into the sample table
SET NOCOUNT ON;
BEGIN
BEGIN TRANSACTION;
DECLARE @i INTEGER = 0;
WHILE (@i < 10000)
BEGIN
INSERT INTO dbo.Tab_A (Col1, Col2) VALUES (@i, @i);
SET @i+=1;
END;
COMMIT TRANSACTION;
END;
GO
-- There are much more rows with value 1 than rows with other values
INSERT INTO dbo.Tab_A (Col1, Col2) VALUES (1, 1)
GO 500000
SET NOCOUNT OFF;
GO
CREATE INDEX IDX_Tab_A_Col1 ON dbo.Tab_A
(
[Col1]
);
GO
CREATE INDEX IDX_Tab_A_Col2 ON dbo.Tab_A
(
[Col2]
);
GOLa distribuzione dei dati nella tabella dbo.Tab_A non è uniforme, ci sono molte più righe (500.001 righe su un totale di 510.000) con valore 1 nelle colonne Col1 e Col2 rispetto alle righe con altri valori.
Consideriamo la seguente stored procedure che effettua una semplice ricerca sulla tabella dbo.Tab_A per le colonne Col1 e Col2.
CREATE OR ALTER PROCEDURE dbo.Tab_A_Search
(
@ACol1 INTEGER
,@ACol2 INTEGER
)
AS BEGIN
SELECT * FROM dbo.Tab_A WHERE (Col1 = @ACol1) AND (Col2 = @ACol2);
END;
GODurante la compilazione iniziale della stored procedure, le statistiche disponibili per le colonne interessate nel predicato WHERE vengono utilizzate per identificare distribuzioni non uniformi e valutare i predicati parametrizzati più “a rischio”, fino a tre predicati su tutti quelli disponibili. Il predicato utilizzato nella stored procedure interessa le colonne Col1 e Col2, gli indici non cluster creati su tali colonne hanno dato luogo alla creazione delle relative statistiche.
La query seguente mostra gli step dell’istogramma che ritraggono la distribuzione dei dati nella colonna Col1.
SELECT
sh.*
FROM
sys.stats AS s
CROSS APPLY
sys.dm_db_stats_histogram(s.object_id, s.stats_id) AS sh
WHERE
(name = 'IDX_Tab_A_Col1')
AND (s.object_id = OBJECT_ID('dbo.Tab_A'));
GOL’output è rappresentato nella figura seguente. Osserviamo che range_high_key con il valore 1 ha 500.001 record, mentre la maggior parte degli altri valori conta solo pochi record.
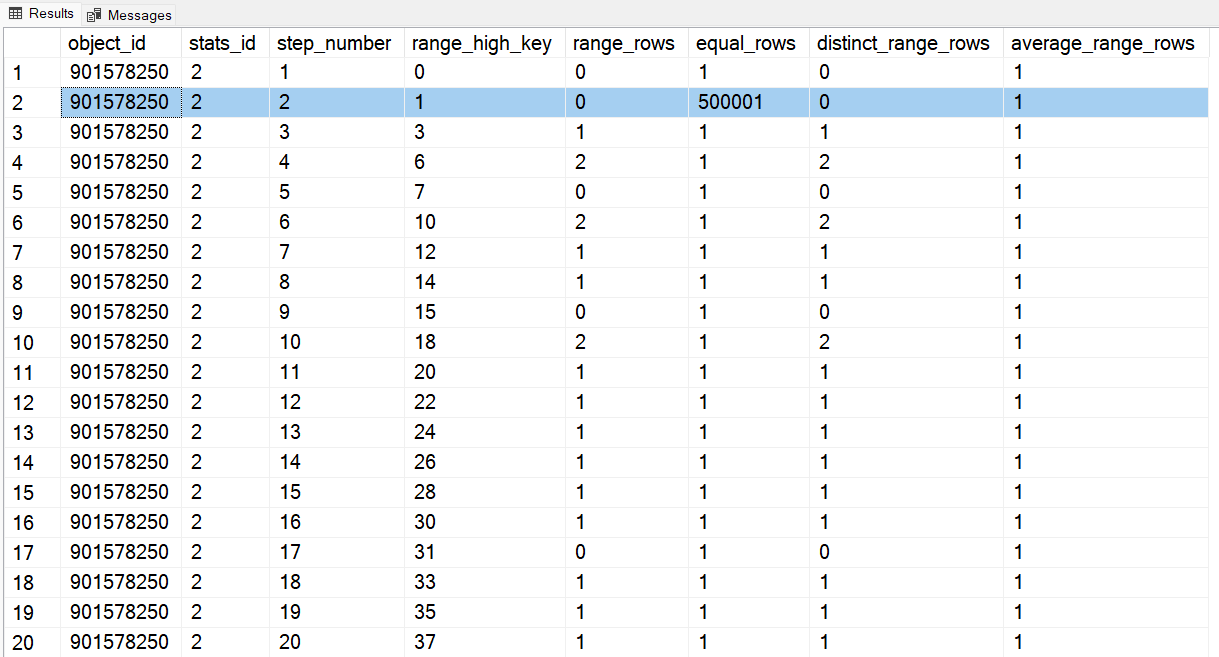
Situazione analoga per l’indice IDX_Tab_A_Col1.
La prima esecuzione della stored procedure dbo.Tab_A_Search valorizza a 1 i parametri @ACol1 e @ACol2 che corrisponde al data-set di 500K record.
EXEC dbo.Tab_A_Search @ACol1 = 1, @ACol2 = 1;La figura seguente illustra il piano di esecuzione scelto da SQL Server per questa coppia di valori.
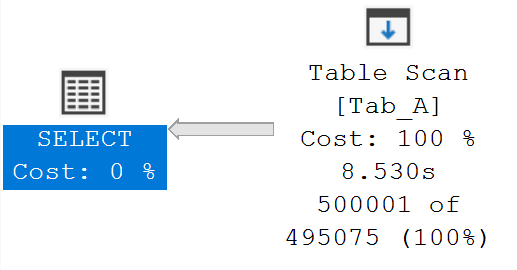
Il piano di esecuzione mostra che è stata scelta una scansione totale della tabella (Table Scan) come metodo di accesso ai dati, il che è molto efficiente per questo scenario in cui vengono restituite molte righe. La memorizzazione nella plan cache e il successivo riutilizzo di questo piano di esecuzione rappresenta il comportamento di default per le query parametrizzate in qualsiasi versione precedente di SQL Server e Azure SQL Database; tuttavia se questo piano di esecuzione venisse utilizzato per recuperare poche righe non sarebbe efficiente!
Con SQL Server 2022 e un database con compatibility level impostato a 160, Parameter Sensitive Plan (PSP) Optimization è in grado di rilevare predicati di uguaglianza come quello utilizzato in questo esempio (WHERE Col1 = @ACol1) e consentirà di mantenere nella plan cache più piani di esecuzione attivi per la stessa query che verranno riutilizzati solo per esecuzioni che restituiscono un numero simile di righe. Ne consegue che durante una esecuzione che restituisce pochissime righe, avremo un piano di esecuzione diverso, più efficiente, con un diverso metodo di accesso ai dati. Verrà quindi utilizzata una operazione di puntamento diretto sull’indice (Seek) al posto di una scansione totale (Scan) della tabella.
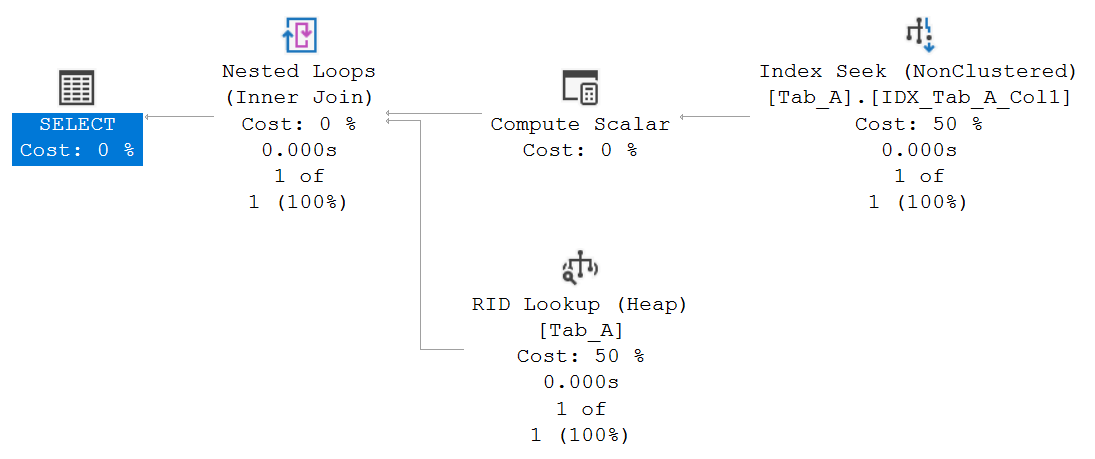
Eseguiamo la stored procedure con diverse coppie di valori.
EXEC dbo.Tab_A_Search @ACol1 = 33, @ACol2 = 33;
GO
EXEC dbo.Tab_A_Search @ACol1 = 33, @ACol2 = 25;
GO
Il piano di esecuzione seguente mostra che, per valori diversi di parametri, è stato scelto un puntamento diretto sull’indice (Seek) molto più efficiente in questo scenario dove vengono restituite poche righe.
Per i piani di esecuzione adatti ad essere ottimizzati con Parameter Sensitive Plan, la compilazione iniziale produce un piano di esecuzione dispatcher che contiene la logica di ottimizzazione (dispatcher expression). Il piano di esecuzione “di tipo” dispatcher è collegato alle possibili varianti di query in funzione della cardinalità dei predicati. Ogni variante è collegata ad un piano di esecuzione nel quale troveremo gli operatori più adeguati a trattare il dataset che si stima venga restituito da quella specifica variante di query.
I piani di esecuzione dispatcher vengono attualizzati automaticamente in caso di modifiche significative alla distribuzione dei dati. I piani di esecuzione collegati alle varianti di query vengono ricompilati in modo indipendente in base alle esigenze. Il trace flag 12619 permette di ottenere informazioni dettagliate all’interno di Query Store circa le ottimizzazioni eseguite da Parameter Sensitive Plan.
La vista di sistema sys.query_store_query_variant permette di monitorare le relazioni tra una query e le sue varianti e consente la creazione di report su tutte le varianti di query associate ad una query con parametri. La query seguente interroga la plan cache e mostra la presenza di due piani di esecuzione attivi per la stessa query, il primo ottimale per l’estrazione di un numero elevato di righe, il secondo ottimale per l’estrazione di poche righe.
SELECT
usecounts
,plan_handle
,objtype
,text
FROM
sys.dm_exec_cached_plans
CROSS APPLY
sys.dm_exec_sql_text (plan_handle)
WHERE
(text LIKE '%Tab_A%')
AND
(objtype = 'Prepared');
GO
Conclusioni
Query Store abilitato by default in SQL Server 2022 unito alla nuova generazione di Intelligent Query Processing permettono di migliorare le performance in alcuni scenari comuni, senza modifiche al codice T-SQL. Parameter Sensitive Plan (PSP) Optimization rappresenta uno di questi miglioramenti perché permette di avere in cache più di piani di esecuzione relativi alla stessa query parametrica risolvendo il famoso problema noto con il nome di Parameter Sniffing!