 UGISS User Group Italiano SQL Server
UGISS User Group Italiano SQL Server
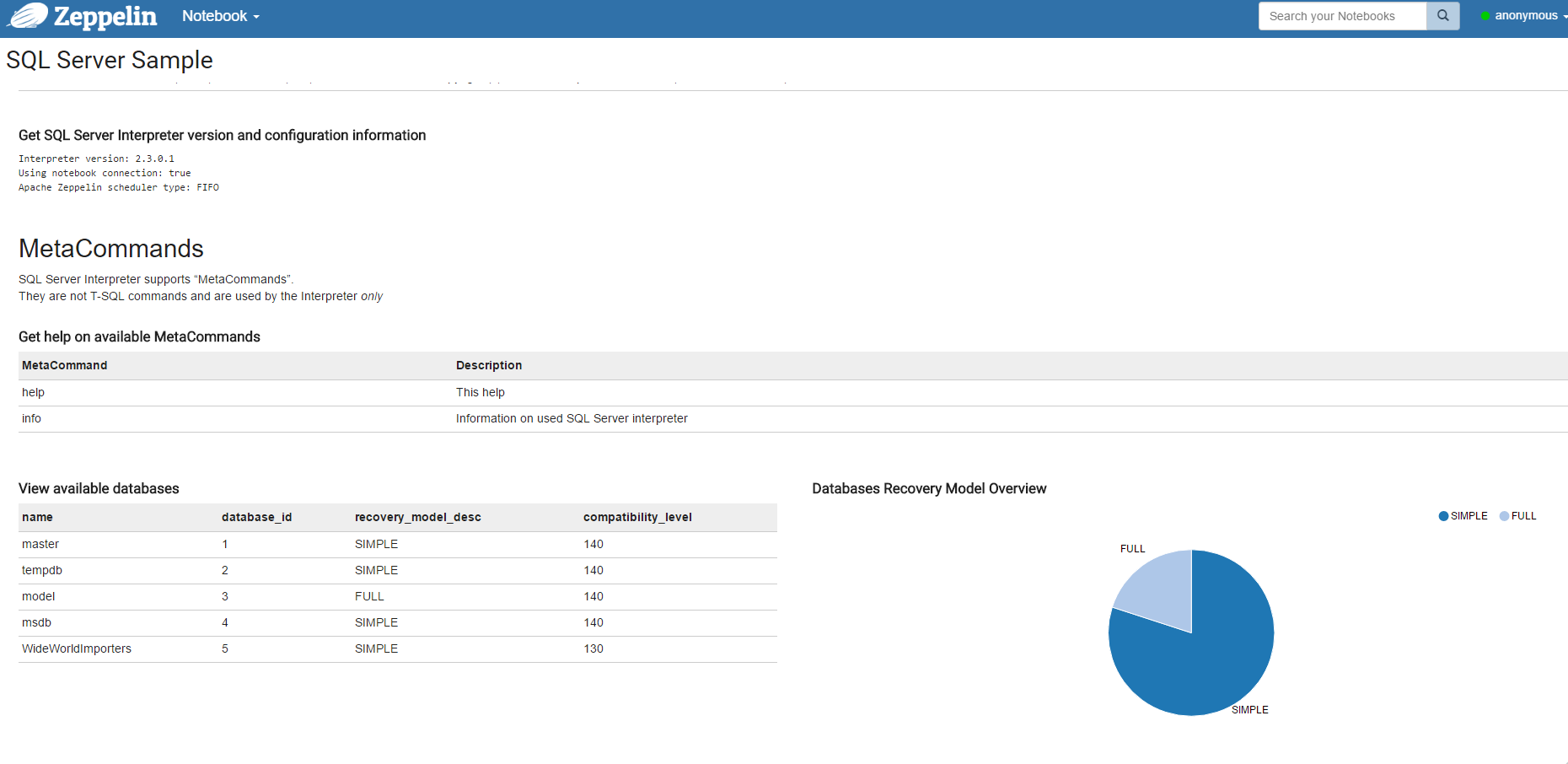
Apache Zeppelin é un “web-based notebook” che permette di eseguire query verso le piú disparate sorgenti dati, anzi Big Data, manipolando il risultato ottenuto per visualizzare tabelle o grafici, mixando il tutto anche con la possibilità di scrivere del markdown e poter organizzare lo spazio del notebook ridimensionando i paragrafi e trascinandoli dove si vuole. Ottimo, insomma, per creare dashboard al volo Ma non solo: personalmente lo trovo fantastico per lavorare sui dati in modo interattivo. Utilissimo chiaramente per chi si occupa di Data Science, è un ottimo strumento anche per tutti coloro che hanno “solamente” a che fare con i dati tutti giorni. Lo scopo di Apache Zeppelin, infatti, é quello di rendere possibile le attivita di
- Data Ingestion
- Data Discovery
- Data Analytics
- Data Visualization & Collaboration
tramite un’interfaccia interattiva a notebook, lanciata in origine da Jupyter (quando ancora si chiamava IPython) e che ha preso piede un po’ ovunque (tanto per citare l’ultima novitá in casa Azure: https://notebooks.azure.com)
Tutto molto bello ma manca il supporto nativo per SQL Server, Azure SQL ed Azure DW.
Dall’inzio del 2015 ho inziato a lavorare su un Interprete specifico per SQL Server, per poter sfruttare al 100% le possibilitá del nostro beneamato engine. Nei giorni scorsi ho rilasciato l’interprete per l’ultima versione stabile di Apache Zeppelin, la 0.6.2, e, dato che tutto é fatto in Java, per semplificare il processo di download ed installazione ho creato e pubblicato un’immagine Docker cosi che sia possibile eseguire Apache Zeppelin senza doversi preoccupare della tecnologia utilizzata per farlo funzionare.
Qui potete trovare i primi di una serie di post che ho in programma di pubblicare per mostrare come poter usare Apache Zeppelin: